|
Fabio Spizzichino and Rachele Foschi
|
It is a very well known result in queueing theory that the output of an infinite
server queue
Mt/G/ (with a Poisson arrival process, then) is Poisson as
well.
(with a Poisson arrival process, then) is Poisson as
well.
Such a closure-type result can be extended in a number of different directions.
Most natural types of extensions can be obtained as follows:
i) by replacing Poisson arrival processes with Mixed Poisson arrival processes
ii) by replacing Poisson arrival processes with M-Poisson processes on the line
iii) by replacing the
Mt/G/ model with a more general transformation,
where each jump Si in the departure process is obtained
by combining an arrival Ti with a random variable Zi:
(being
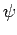
 Ti, Zi
Ti, Zi = Ti + Zi, for the specific scheme of an
infinite server queue).
= Ti + Zi, for the specific scheme of an
infinite server queue).
Z1, Z2,... are assumed to be i.i.d.
The extension in ii) is preliminary, and turns out to be basilar, for the extension in
iii) (see [1]). The latter case can, in its turn, be extended to more general models
with spatial Poisson arrival processes.
Substantially such closure-type results are based on the ``Order
Statistics Property'' (OSP) of the arrival process (see [2] and [3],
for the case in i) and [1] for ii) and iii)).
Also the ``p-thinning Property" of the arrival process (see e.g. [4])
has a fundamental role in this context (see also [5] for some remarks in this
concern).
In the talk, we consider models characterized by generic transformations of
"spatial-mixed Poisson" arrival processes and present a more general (closure-type)
result, that can be obtained in terms of the Order Statistics and p-thinning
properties.
Possibly, we also aim to discuss some aspects in the Bayesian estimation of the
unobservable parameter M of the spatial-mixed Poisson process {N} ({N} being
a conditionally spatial Poisson process, given M).
References
[1] Brown M. (1969). J. Appl. Probability, 6, 453-458.
[2] Huang, W. and Puri, P. (1990). Sankhya, Ser. A, 52, 232-243.
[3] Berg M. and Spizzichino F. (2000). Math. Methods of Oper. Res., 51, 301-314.
[4] Grandell J. (1997). Chapman & Hall, London.
[5] Foschi R. (2005). Tesi di Laurea in Matematica. Universita' "La Sapienza".